
На сегодняшний день обучение машинного зрения для распознавания различных задач очень актуально. Взять, к примеру, автомобильные камеры, в них так же работает программа по распознаванию номерного знака. Но в данном решении небольшое количество объектов, которые необходимо распознать: цифры от 0 до 9 и буквы алфавита. Для обучения распознавания одного объекта-цифры, нейронной сети необходимо предоставить от 10 тысяч фотографий разного ракурса, освещения, удаленности. Чем их больше и чем они сложнее, тем лучше программа будет распознавать его. И вот тут возникает самая большая проблема для обучения большого количества жестов – формирование базы для обучения. 8 тысяч жестов по 10 тысяч фотографий для каждого, получается 80 миллионов фотографий. Если создавать их в течении 1 года и работать каждый день, без выходных, по 8 часов, то нужно всего 27 397 фотографий в час. И да, в интернете такой базы нет, поэтому нужно решить проблему формирования уникальной базы данных. И это только пол беды.
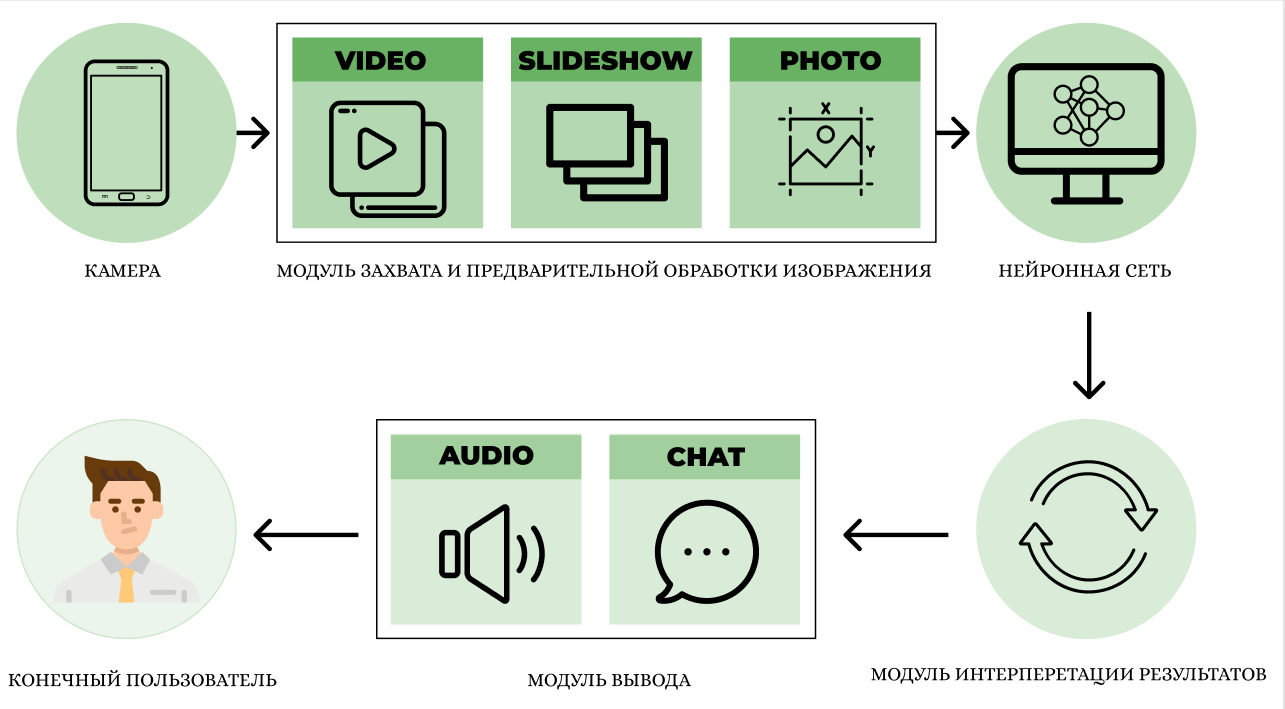
Процесс обучения протекает не быстро, это программно – аппаратный процесс, который сильно потребляет ресурсы компьютера. Данный процесс сравним с 3D рендерингом или майнингом, нагрузка может идти на процессор, видеокарту или оперативную память. Временные затраты на обучение, на среднем, «домашнем» компьютере, 1 жеста, могут достигать 5 суток.
Также, нужно выбрать технологию для классификации изображений. Лучшие для нашего проекта являются: Mediapipe, TensorFlow, YOLO V5. Мы видели статью Новосибирских ученных, которая базируется на Mediapipe, с 92% распознавания. Но у данной технологии есть существенные ограничения по оборудованию конечного пользователя – высоко производительное, ограничения с обнаружением на расстоянии, существенные временные затраты на обучение. Не будем вдаваться в технические подробности и причины выбора той или иной технологии, но для нашей задачи была выбрана технология YOLO V5.

Исходя из всего сказанного, перед тем как начать штурмовать этот Эверест, нужно сесть и основательно просчитать свои временные затраты. Но беда в том, что просто сесть и просчитать невозможно, нужно экспериментировать с небольшими объемами данных и по ходу экспериментов делать вывод с учетом масштабирования. На данный момент мы потратили 8 месяцев для того, чтобы отработать механизм формирования графической базы для обучения со скоростью, в среднем, 800-1000 изображений в минуту, для этого нужна команда из 2-х человек. При этом, изображения дают высокий % распознавания, после обучения искусственного интеллекта до 97%.
С одной задачей мы справились, теперь мы заняты подбором аппаратных решения для обучения такого объема данных в короткие сроки. Это реально, у нас уже есть наработки по требуемым характеристикам серверов, на днях приступим к их сборке. После отработки последнего этапа, наша команда перейдет к обучению большого объема статичных жестов. Параллельно, следующим этапом, пойдет построение процессов распознавания динамических жестов, так как они отличаются от статичных. Наработки в этом направлении так же имеются.

В итоге, в ходе проводимой работы мы преследуем долгую цель – обучить нейронную сеть русскому языку жестов, но также, мы можем осуществлять небольшие отступления в виде обучения отдельным жестам, которые могут работать в качестве элементов управления в современных цифровых решениях: ТВ, автомобили, цифровые платформы и тд.
Сейчас, проект «Сурдолайт», готов рассмотреть участие инвестора для достижения поставленной цели. С промежуточными результатами проекта можно ознакомится на нашей странице. Проект разрабатывается в рамках корпоративного акселератора группы компаний INKOM.

0 комментариев